
Geschätzte Lesezeit: 6 Minuten
Wichtige Erkenntnisse
- Paradigmenwechsel: Apple verabschiedet sich von traditionellem Reinforcement Learning (RLHF) für UI-Design und setzt auf „Designer-Native“-Workflows.
- Effizienz-Durchbruch: Ein mit nur 181 Skizzen trainiertes Modell (basierend auf Qwen3-Coder) übertraf die Leistung des proprietären Giganten GPT-5.
- Konkrete Daten: Direkte Design-Bearbeitungen führten zu einer Übereinstimmungsrate von 76,1 % bei der Qualitätsbewertung, verglichen mit nur 49,2 % bei einfachen Rankings.
- Open-Source-Basis: Apple nutzte die Qwen2.5-Coder-Familie als Fundament, um die Generalisierbarkeit der neuen Feedback-Methode zu testen.
- Qualität vor Quantität: Die Studie beweist, dass kleine Mengen hochqualitativer Experten-Daten effektiver sind als riesige Datensätze mit binärem Feedback.
 *Einblick in Apples Forschungslabore: Maschinelles Lernen trifft auf menschliche Design-Intuition.*
*Einblick in Apples Forschungslabore: Maschinelles Lernen trifft auf menschliche Design-Intuition.*
Apple erforscht weiterhin intensiv, wie generative künstliche Intelligenz (KI) die Entwicklungspipelines von Apps nicht nur beschleunigen, sondern qualitativ verbessern kann. Während frühere Ansätze sich primär auf die reine Lauffähigkeit von Code konzentrierten, zielt die neueste Forschung auf eine viel komplexere Variable ab: ästhetische und funktionale Designqualität.
Die Ergebnisse deuten auf eine signifikante Verschiebung in der Art und Weise hin, wie KI-Modelle in Zukunft trainiert werden könnten – weg von massenhaften Datenmengen, hin zu präzisem Expertenwissen.
Der Kontext: Von UICoder zur Design-Intelligenz
Vor wenigen Monaten veröffentlichte ein Apple-Forschungsteam eine bemerkenswerte Studie über das Training von KI zur Erstellung funktionaler Benutzeroberflächen (UI). Das Ziel dieser früheren Untersuchung war pragmatisch: Der generierte Code sollte kompilierbar sein und grob den Anforderungen des Nutzers entsprechen.
Das Resultat dieser Bemühungen war UICoder, eine Familie von Open-Source-Modellen, die bereits solide Ergebnisse lieferte. Doch funktionierender Code ist nicht gleichbedeutend mit gutem Design. Eine Benutzeroberfläche kann technisch fehlerfrei sein, aber dennoch die Prinzipien der User Experience (UX) verletzen. Genau hier setzt die neue Forschungsarbeit an.
Die neue Studie: Designer-Feedback als Trainingsmotor
Ein Teil des Teams hinter UICoder hat nun ein neues Paper mit dem Titel „Improving User Interface Generation Models from Designer Feedback“ veröffentlicht. Die zentrale These der Forscher ist eine direkte Kritik an den aktuellen Industriestandards.
Die Grenzen von RLHF
Bisherige Methoden, insbesondere das „Reinforcement Learning from Human Feedback“ (RLHF), erweisen sich als unzureichend für visuelle Aufgaben. Bei RLHF bewerten Menschen den Output eines Modells oft binär (Daumen hoch/runter) oder durch einfaches Ranking.
Die Apple-Forscher argumentieren, dass diese Methoden nicht mit den Arbeitsabläufen professioneller Designer übereinstimmen. Sie ignorieren die „reiche Rationale“, die notwendig ist, um ein UI-Design fundiert zu kritisieren und zu verbessern. Ein einfaches „Besser“ oder „Schlechter“ erklärt der KI nicht, warum ein Layout nicht funktioniert – sei es aufgrund mangelnden Kontrasts, schlechter Platzierung oder inkonsistenter Typografie.
Der innovative Ansatz
Um dieses Defizit zu beheben, wählten die Wissenschaftler einen neuen Weg. Anstatt Laien einfache Bewertungen abgeben zu lassen, integrierten sie 21 professionelle Designer direkt in den Trainingsprozess. Diese Experten nutzten ihre gewohnten Werkzeuge:
- Kommentare: Detaillierte textliche Erklärungen zu Designfehlern.
- Skizzen: Visuelle Korrekturen direkt auf den Entwürfen.
- Hands-on-Edits: Direkte Bearbeitung des Codes oder der Layouts.
Diese Vorher-Nachher-Daten wurden anschließend genutzt, um das Modell fein abzustimmen (Fine-Tuning). Das Belohnungsmodell (Reward Model) lernte somit nicht nur, was „gut“ ist, sondern verstand die konkreten visuellen Verbesserungen, die ein erfahrener Designer vornehmen würde.
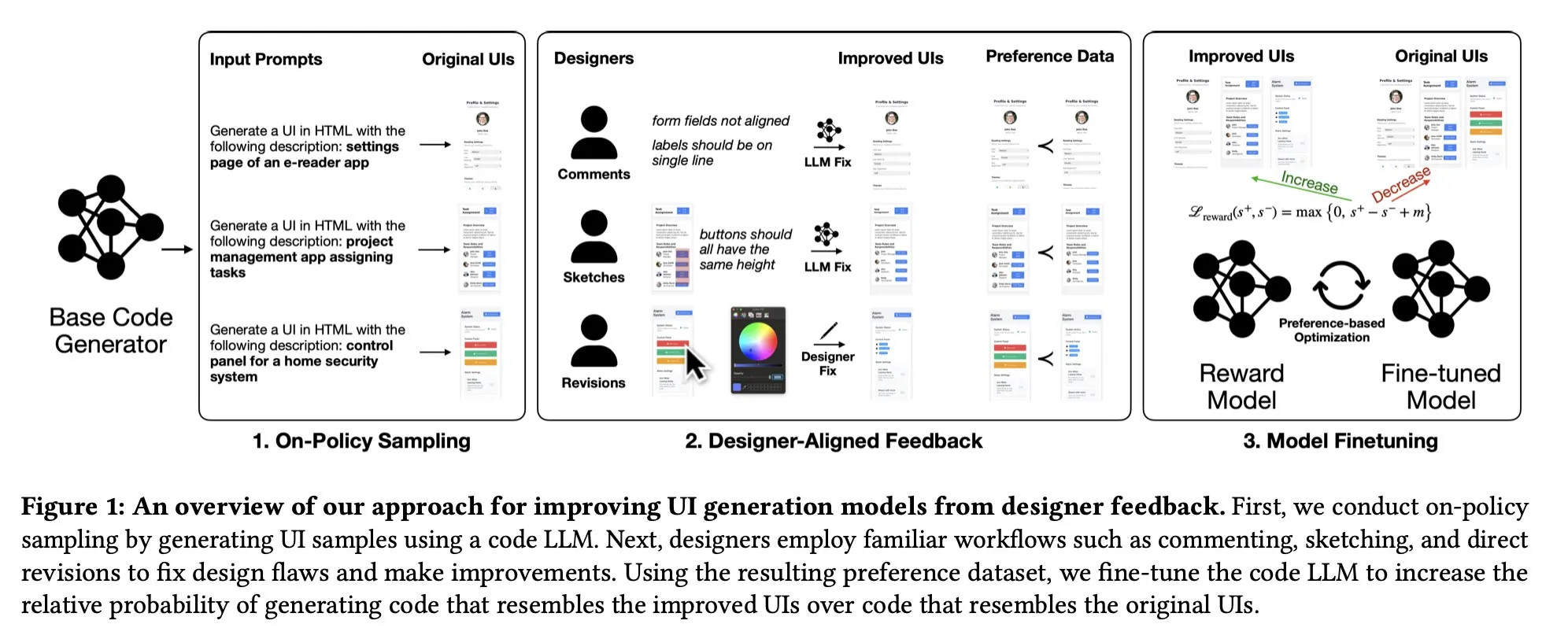 *Das Framework der Studie: Designer geben Feedback durch Skizzen und Edits, um das Belohnungsmodell zu trainieren.*
*Das Framework der Studie: Designer geben Feedback durch Skizzen und Edits, um das Belohnungsmodell zu trainieren.*
Das Setup: Präzision durch Expertenwissen
Die methodische Strenge der Studie unterstreicht die Relevanz der Ergebnisse. Die Teilnehmergruppe bestand aus Designern mit einer Berufserfahrung zwischen 2 und über 30 Jahren. Sie deckten diverse Bereiche ab, von UI/UX-Design über Produktdesign bis hin zu Service-Design.
Datenerhebung und Verarbeitung
Insgesamt sammelten die Forscher 1.460 Annotationen. Diese wurden in gepaarte „Präferenz“-Beispiele umgewandelt. Dabei wurde die ursprüngliche, vom Modell generierte Schnittstelle der vom Designer verbesserten Version gegenübergestellt.
Das Training des Belohnungsmodells folgte einem klaren Prozess:
- Input: Ein gerendertes Bild (Screenshot der UI) und eine natürlichsprachliche Beschreibung.
- Verarbeitung: Diese Eingaben erzeugen einen numerischen Wert (Reward), der so kalibriert ist, dass visuell hochwertigere Designs höhere Punktzahlen erzielen.
- Rendering-Pipeline: Um HTML-Code bewertbar zu machen, nutzte das Team Automatisierungssoftware, die den Code zunächst in Screenshots umwandelte.
Als Basismodelle für die Generierung nutzte Apple Qwen2.5-Coder. Später wurde das durch Designer trainierte Belohnungsmodell auch auf kleinere und neuere Varianten der Qwen-Familie angewendet. Dies diente dazu, die Skalierbarkeit und Generalisierbarkeit des Ansatzes über verschiedene Modellgrößen hinweg zu validieren.
Interessanterweise ähnelt das Framework strukturell einer traditionellen RLHF-Pipeline. Der entscheidende Unterschied liegt in der Qualität des Signals: Es stammt aus nativen Designer-Workflows und nicht aus vereinfachten Rankingsystemen.
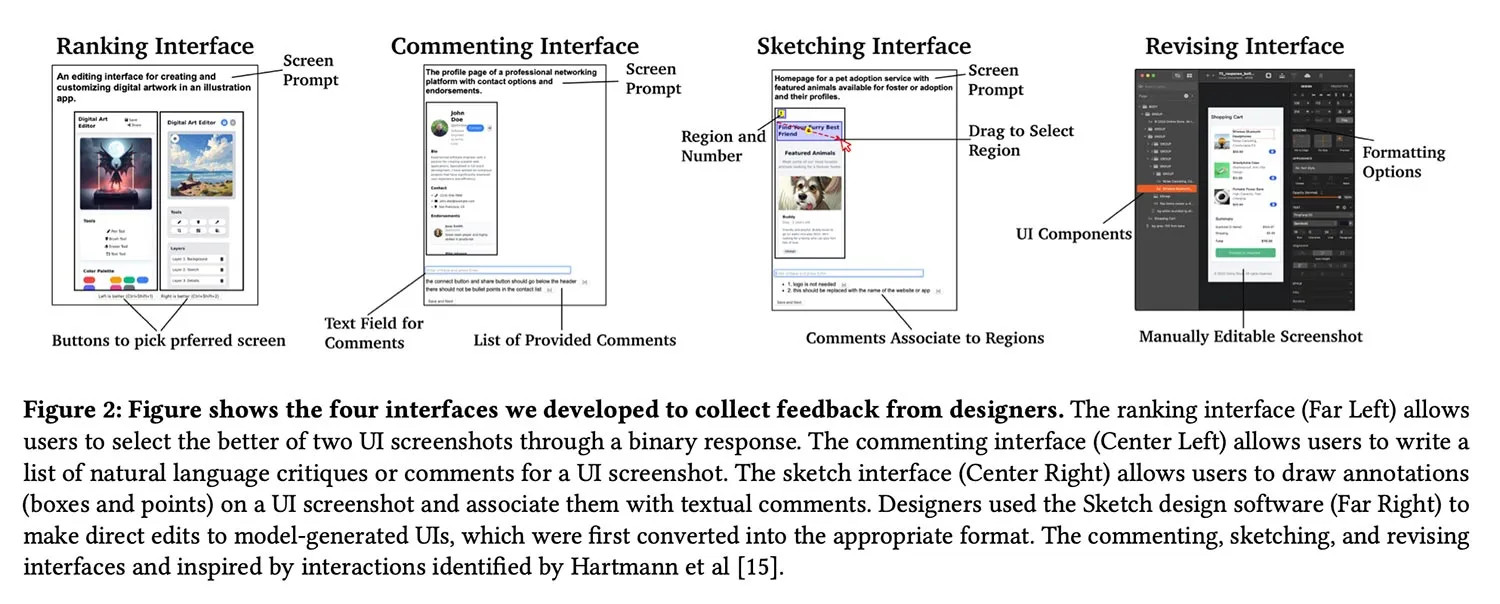 *Vergleich der Trainingsdaten: Links das ursprüngliche Modell, rechts die durch Designer optimierte Version.*
*Vergleich der Trainingsdaten: Links das ursprüngliche Modell, rechts die durch Designer optimierte Version.*
Die Ergebnisse: Qualität schlägt Modellgröße
Die zentrale Frage lautet: Hat dieser Aufwand zu messbaren Verbesserungen geführt? Die Antwort der Forscher ist ein klares Ja, allerdings begleitet von wichtigen Nuancen, die für Analysten und Entwickler gleichermaßen interessant sind.
Generell produzierten Modelle, die mit nativen Designer-Feedbacks (insbesondere Skizzen und direkten Überarbeitungen) trainiert wurden, signifikant hochwertigere UIs als die Basismodelle. Sie übertrafen auch solche Versionen, die mit herkömmlichen Ranking-Daten trainiert wurden.
Der GPT-5 Vergleich
Ein spezifisches Datenpunkt sticht besonders hervor: Das leistungsstärkste Modell der Studie (Qwen3-Coder, feinabgestimmt mit Skizzen-Feedback) übertraf in den Tests sogar GPT-5.
Das Bemerkenswerte daran ist die Effizienz der Datenbasis. Dieses Ergebnis wurde mit lediglich 181 Skizzen-Annotationen erzielt. Dies widerlegt die gängige Annahme, dass nur massive Datenmengen zu Leistungssteigerungen führen.
„Unsere Ergebnisse zeigen, dass das Feinabstimmen mit unserem skizzenbasierten Belohnungsmodell konsistent zu Verbesserungen der UI-Generierungsfähigkeiten bei allen getesteten Baselines führte. Wir zeigen auch, dass eine kleine Menge hochwertigen Experten-Feedbacks effizient ermöglichen kann, dass kleinere Modelle größere proprietäre LLMs in der UI-Generierung übertreffen.“ – Auszug aus der Studie.
Die Herausforderung der Subjektivität
Ein kritischer Aspekt bei der Bewertung von Design ist die inhärente Subjektivität. Was eine „gute“ Benutzeroberfläche ausmacht, kann je nach Betrachter variieren. Dies führte in der Studie zu einer hohen Varianz bei rein ranking-basierten Bewertungen.
Die Forscher stellten fest:
- Bei einfachen Rankings stimmten unabhängige Bewerter nur in 49,2 % der Fälle mit den Entscheidungen der Designer überein – ein Ergebnis, das kaum besser ist als ein Münzwurf.
- Wenn Designer jedoch Skizzen anfertigten, stieg die Übereinstimmung auf 63,6 %.
- Bei direkten Bearbeitungen (Edits) kletterte die Zustimmung sogar auf 76,1 %.
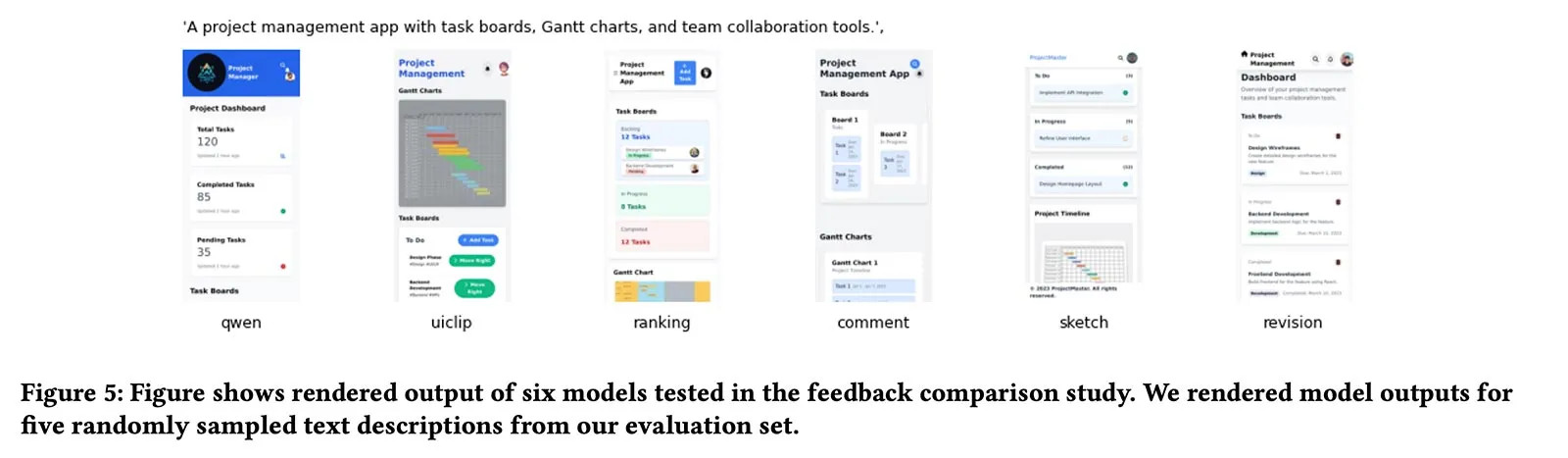 *Beispiele generierter Interfaces: Die Feinabstimmung führt zu saubereren, logischeren Layouts.*
*Beispiele generierter Interfaces: Die Feinabstimmung führt zu saubereren, logischeren Layouts.*
Analyse: Warum dies den Markt verändert
Diese Studie hat Implikationen, die weit über Apple hinausgehen. Für Investoren und Marktbeobachter im Technologie-Sektor ergeben sich hieraus drei wesentliche Ableitungen:
- Small Data wird wertvoller: Die Ära, in der „Big Data“ das einzige Heilmittel war, neigt sich dem Ende zu. Kuratierte, hochspezifische Datensätze („Small Data“) von Experten werden zum entscheidenden Wettbewerbsvorteil. Dies senkt die Eintrittsbarrieren für spezialisierte KI-Anwendungen drastisch, da keine Milliarden-Budgets für Rechenleistung benötigt werden.
- Rolle der Experten: KI ersetzt Experten nicht, sie benötigt sie mehr denn je als Lehrer. Die Rolle des Designers verschiebt sich vom „Ersteller“ zum „Kurator und Trainer“.
- Open Source Validierung: Dass Apple, bekannt für sein geschlossenes Ökosystem, auf Qwen-Modelle (Open Source) zurückgreift und deren Leistungsfähigkeit demonstriert, stärkt das Vertrauen in die Open-Source-KI-Community.
Die Fähigkeit, präzise zu definieren, was „besser“ bedeutet – durch visuelle Beispiele statt abstrakter Wahlmöglichkeiten – löst eines der ältesten Probleme der KI-Ausrichtung. Wenn Modelle lernen, menschliche Intentionen durch Demonstration statt durch binäre Wahl zu verstehen, steigt die Anwendbarkeit in subjektiven Feldern wie Kunst, Design und Strategie exponentiell an.
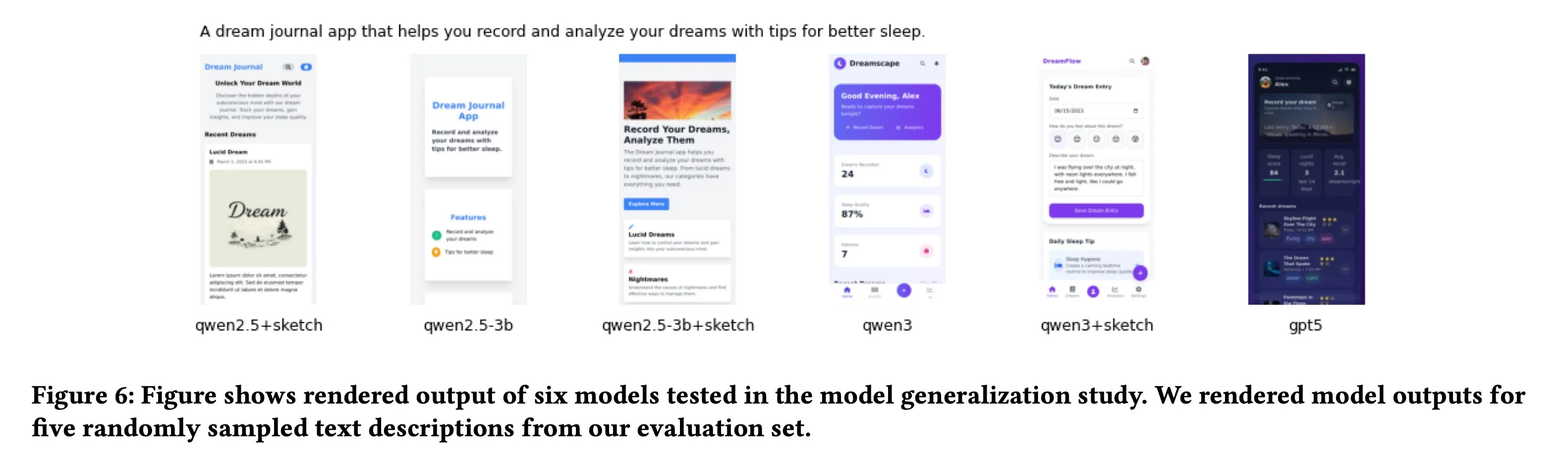 *Detailansicht der Verbesserungen: Konsistente Abstände und klare Hierarchien durch Experten-Training.*
*Detailansicht der Verbesserungen: Konsistente Abstände und klare Hierarchien durch Experten-Training.*
Häufig gestellte Fragen (FAQ)
Was ist der Unterschied zwischen RLHF und dem neuen Ansatz von Apple?
RLHF (Reinforcement Learning from Human Feedback) nutzt meist einfache Rankings (Design A ist besser als B). Apples neuer Ansatz integriert „Designer-Native“-Feedback wie Skizzen, Kommentare und direkte Code-Änderungen. Dies liefert der KI den Kontext und das „Warum“ hinter einer Verbesserung, was zu präziseren Lernergebnissen führt.
Warum nutzte Apple das Qwen-Modell anstelle eines eigenen?
Die Nutzung von Qwen2.5-Coder und Qwen3-Coder ermöglichte es den Forschern, ihre Methode auf einer bekannten, leistungsfähigen Open-Source-Basis zu testen. Dies erleichtert die Vergleichbarkeit der Ergebnisse mit anderen Studien und demonstriert, dass die Methode modellunabhängig funktioniert. Es zeigt zudem Apples pragmatischen Ansatz, die besten verfügbaren Werkzeuge für die Forschung zu nutzen.
Bedeutet dies, dass KI bald Designer ersetzen wird?
Nein, die Studie deutet eher auf das Gegenteil hin. Die KI benötigt hochwertiges Feedback von erfahrenen Designern, um überhaupt gute Ergebnisse zu liefern. Die Rolle des Designers entwickelt sich weiter: Er wird zum Dirigenten, der die KI anleitet und korrigiert. Die Technologie dient als Multiplikator für menschliche Kreativität und Effizienz, nicht als Ersatz.
Wie zuverlässig sind die Ergebnisse im Vergleich zu GPT-5?
Die Forscher geben an, dass ihr spezialisiertes Modell in der spezifischen Aufgabe der UI-Generierung besser abschnitt als GPT-5. Dies liegt an der Spezialisierung: Ein kleineres, hochspezialisiertes Modell schlägt oft ein riesiges generalistisches Modell in einer konkreten Nische. Das Ergebnis validiert den Trend hin zu spezialisierten KI-Agenten für Fachbereiche.
Referenzen
- Apple Machine Learning Research: Improving User Interface Generation Models from Designer Feedback
- Originalstudie (Arxiv): UICoder: Finetuning Large Language Models to Generate User Interface Code
- Quelle: 9to5Mac – Apple AI UI Research
- Qwen Modell-Familie: Qwen2.5-Coder Technical Report